5 Data Structures
CHAPTER OVERVIEW NEEDED??
5.1 Tidy Data
[INSERT QUIP ABOUT TIDY DATA OR QUOTE]
In Chapter 2 when we introduced the R programming language as our preferred tool for marketing analytics we briefly referenced the concept of “tidy” data. It is important to understand tidy data principles because they are the motivation for many packages that make data processing a less tedious exercise. Hadley Wickham proposes three rules that make a dataset tidy:
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
[INSERT FIGURE, POSSIBLY https://r4ds.had.co.nz/tidy-data.html#fig:tidy-structure]
Wickham has even reimagined the data.frame object type that exists in base R with a version that is more “tidy”. It is a tbl_df object, also referred to as a “tibble”. For example, tibbles do not add rownames because rownames are values that should be stored in their own column. Tibbles are more convenient than data.frames for other reasons, which is also why we recommend using them.
Not all datasets are tidy,
EUROMONITOR EXAMPLE???
5.2 Relational Data
In programming there is a matra of “Don’t repeat yourself” (DRY). It is a principle instilled in software developers because unnecessary repetition makes code less efficient, requires additional time to maintain, and can quickly become out of sync. In code, this means creating functions or classes. In databases, this is usually done through data normalization. The degree of data normalization is the extent to which the data is replicated in multiple places within a database. Highly normalized means that a single data point only appears in one place. In contrast, a highly denormalized dataset means that a single data point may appear in multiple places. For example, …
COMPLETEJOURNEY AS AN EXAMPLE???
Databases use “keys” in order to keep track of related data points. The word “key” simply refers to values in one or more columns that identify each row. In the example above column XYZ was the key. This column exists in both tables and refers to the same row. When working with real-world data it is important to understand how keys are represented in your dataset. There are names for two different types of keys that work together:
- Primary key
- Foreign key
A primary key is one or more columns in a dataset that are always unique and non-missing for each row. Database architects can put explicit constraints on database tables so that duplicates are never entered into the data, even by mistake. This is a good practice for preserving data integrity. In the example above, the primary key is …
A foreign key is just the existence of a primary key in a different table from where it is defined. In the example above column XYZ was the primary key in the first dataset, but it existed in the second dataset for us to join on. In this situation it called the foreign key in the second dataset because it is a key, but it refers to a different dataset where it is a primary key. A great discussion about keys is available in Chapter 13 Section 3 of R for Data Science (Wickham, Grolemund, and Garrett 2017)
Below is an entity-relationship diagram (ERD). This visually represents the relationships between a set of tables so that analysts can get a high-level view of what data exists in each dataset and how to bring them together through joins.
[INSERT COMPLETE JOURNEY DIAGRAM]
[INSERT SOME COMMENTARY ABOUT HOW THE COMPLETE JOURNEY DATASET IS ORGANIZED AND WHY]
SHOULD WE REVISIT SPREAD/GATHER UNDER THE BACKDROP OF NORMALIZATION?
5.3 Joins
If database architects “normalize” a database by creating multiple tables that reference each other, then we need a way to bring the data back together from each of these sources. The process of combining columns from two or more tables is called a “join”. “Joining” tables may also be described as “merging”. These phrases usually mean the same thing. The tricky part about joining datasets is understanding how observations in each set should be matched and how to handle instances where the data is missing from one of the tables. One of the most effective ways to learn the behavior of different joins is to use venn diagrams. Below is a comprehensive outline of join operations. You will notice that depending on the type of join certain records will be retained. For example, the inner_join() function will only retain records if they both exist in the dataset.
[INSERT IMAGE HERE] SOMETHING LIKE https://r4ds.had.co.nz/diagrams/join-venn.png
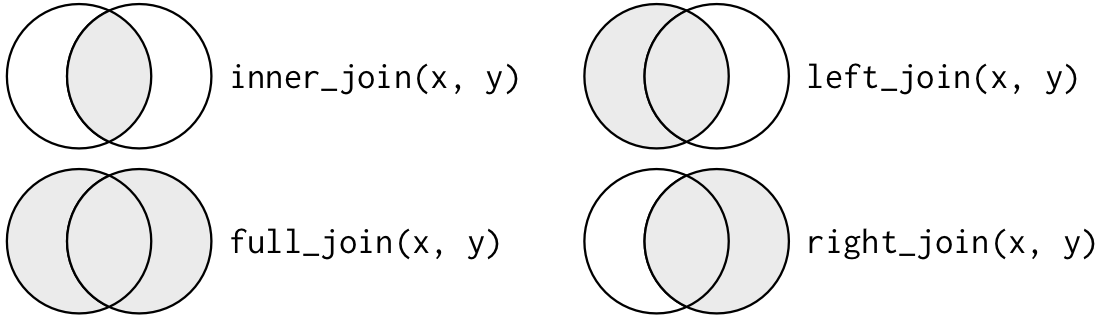{kind=link}
You will also notice in the join reference above how the observations are matched. Typically, you will choose one column and whereever there is a match between the datasets, then the rows will be combined having now columns from both datasets together for the same observation. The one or more columns used to match records is typically called the join “key”.
Consider a simple example where we have one dataset with three columns, the first is a record ID column and a second dataset with 2 columns, its first column is also a record ID column. We will assume the majority of records should have matching IDs between the two datasets. If we would like to “join” the second dataset into the first, then we should use the left_join() function. This function takes the first dataset provided, keeping all of its rows regardless of whether a matching record is found in the second dataset.
#left_join code hereAll of the columns in the second dataset are now added to the first dataset. In this example, that means only one additional column. The ID column is not duplicated after the merge because that information is reflected in the ID column from the first dataset. For readers with knowledge of SQL programming, the join functions in R perform exactly as their counterparts in SQL. For readers with knowledge of Excel this is akin to using the VLOOKUP function or a combination of INDEX-MATCH to pull records from another dataset.
SHOULD WE EXPLICITLY SHOW THE TRANSLATION FROM VLOOKUP TO LEFT_JOIN()? OR INDEX-MATCH?
As depicted in the joins reference diagram there are different join types for returning records from both datasets, all from one dataset, or only the overalapping records. For example, the outer_join() function combines the rows that match on the join key(s) and retains all of the unmatched rows from each dataset. This is also sometimes referred to as a “full join” since it retains the full set of records from both datasets.
#outer_join code hereOne join function that is unique is the anti_join() function. This join returns only the rows that are not matched in the second dataset. This is particularly useful for diagnosing what is not matching. If you think about its behavior, it should, together with the inner_join() function span all the records in the first dataset you provide. This is because either the records are matched via inner_join() or they are not matched and identifed via anti_join(). Below is an example which highlights that 95% of records are matched between the two datasets. The remaining 5% are returned via the anti_join() function for us to further inspect.
#inner_join and anti_join code hereReferences
Wickham, Hadley Grolemund, and Garrett. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 1st ed. Sebastopol, California: O’Reilly Media, Incorporated. https://r4ds.had.co.nz.